Transformer架构
一、注意力机制
1.为什么提出注意力机制?
RNN难以处理长距离的序列信息,且无法并行的处理。CNN能够并行计算,但是是通过窗口来编码,所以更侧重于捕获局部信息,难以建模长距离的语义依赖。而注意力机制能够获取全局信息。
2.注意力机制实现
这里介绍最常见的 Scaled Dot-product Attention 注意力机制。
其有三个核心变量:Q,K,V。其中 Q , K , V 尺度如下:$\boldsymbol{Q}\in\mathbb{R}^{m\times d_k}, \boldsymbol{K}\in\mathbb{R}^{n\times d_k}, \boldsymbol{V}\in\mathbb{R}^{n\times d_v}$ 。通过计算 Q 和 K 的相关性,再对所有 V 加权求和,得到最后的加权融合信息,他会让有价值的信息获得更高权重。其一共包含2个步骤:
1.计算注意力权重
首先使用相似度函数(一般是点积)计算每一个 query 向量和所有 key 向量之间的关联程度。对于长度为 m 的 Query 序列和长度为 n 的 Key 序列,该步骤会生成一个尺寸为 m * n 的注意力分数矩阵(每个元素表示一个查询对某个 K 的匹配程度)。
由于点积可以产生任意大的数字,这会破坏训练过程的稳定性。因此注意力分数还需要乘以一个缩放因子来标准化它们的方差,然后用一个 softmax 标准化。这样就得到了最终的注意力权重 $w~ij~$, 表示第 $i$ 个 query 向量与第 $j$ 个 key 向量之间的关联程度。
2.更新 token embeddings
将权重 $w~ij~$与对应的 value 向量 $\boldsymbol{v}1,…,\boldsymbol{v}_n$ 相乘以获得第 $i$ 个 query 向量更新后的语义表示 $\boldsymbol{x}_i’ = \sum{j} w_{ij}\boldsymbol{v}_j$ 。
公式可以表示为:
实际上他就是三个矩阵 $m\times d_k,d_k\times n, n\times d_v$ 相乘,最后得到与 Q 相同尺度的 $m\times d_v$ 矩阵。
3.自注意力
在Transformer 的 Encoder 结构中使用的是自注意力,他是计算本身序列中每个元素对其他元素的注意力分布,通过给 Q、K、V 的输入传入同一个参数实现。
4.掩码自注意力
掩码的作用是遮蔽一些特定位置的 token,模型在学习的过程中,会忽略掉被遮蔽的 token。使用注意力掩码的核心动机是让模型只能使用历史信息进行预测而不能看到未来信息。
5.多头注意力
Multi-head Attention 首先通过线性映射将 Q , K , V 序列映射到特征空间,每一组线性投影后的向量表示称为一个头 (head),然后在每组映射后的序列上再应用 Scaled Dot-product Attention:
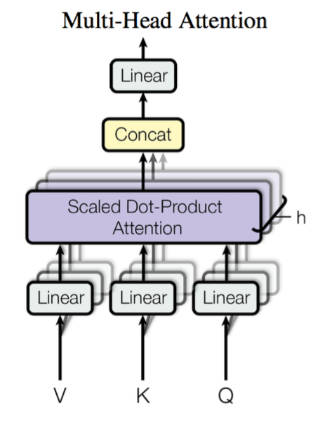
每个注意力头负责关注某一方面的语义相似性,多个头就可以让模型同时关注多个方面。
其中$\boldsymbol{W}_i^Q\in\mathbb{R}^{d_k\times \tilde{d}_k}, \boldsymbol{W}_i^K\in\mathbb{R}^{d_k\times \tilde{d}_k}, \boldsymbol{W}_i^V\in\mathbb{R}^{d_v\times \tilde{d}_v}$ 是映射矩阵,每个头的 Q , K , V 是一样的,映射矩阵不一样。h 是注意力头的数量。最后,将多头的结果拼接起来就得到最终的结果序列。多头就是多做几次 Scaled Dot-product Attention,然后把结果拼接。
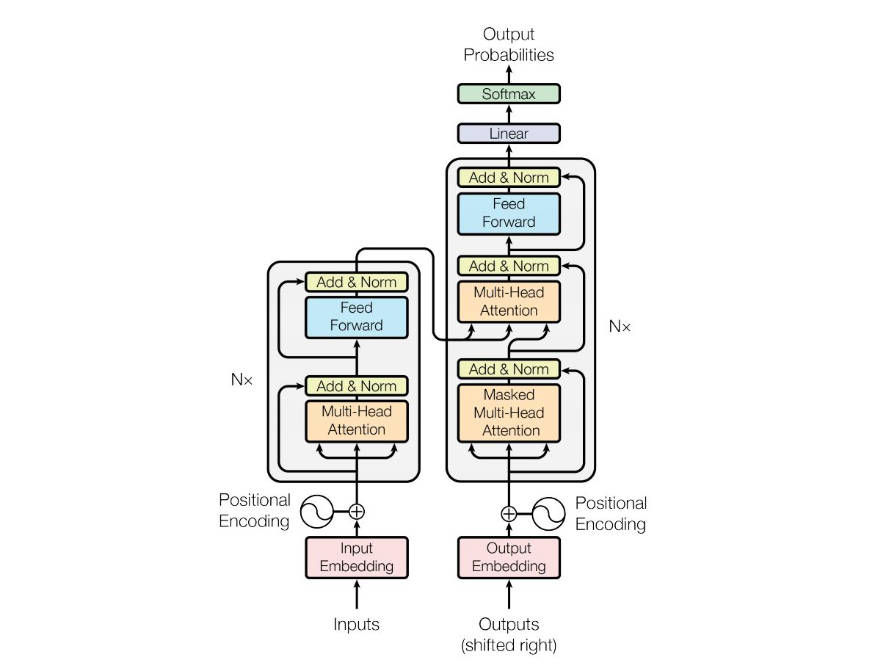
二、Transformers
Transformers架构如下所示: